Publications
A collection of my research work.
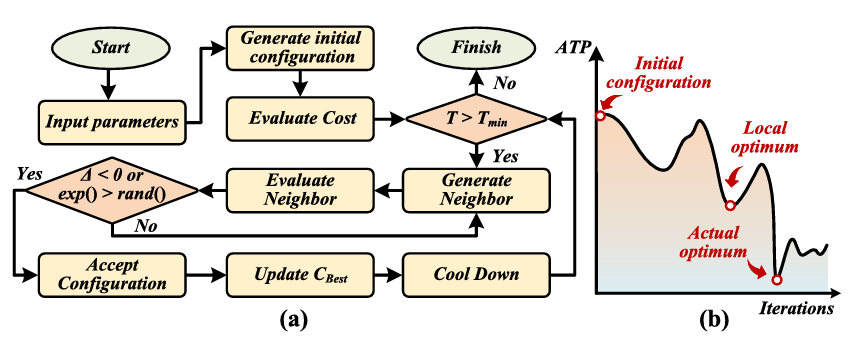
Auto-Mult: A Self-Optimizing Integer Multiplier via Hybrid Decomposition and Automated Parameter Search
Yan Xu, Jianbo Guo, Mengquan Li, Hao Xiao
IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems 2026
Auto-Mult is a self-optimizing integer multiplier using hybrid decomposition and automated parameter search, targeting FPGA-based cryptographic hardware accelerators.
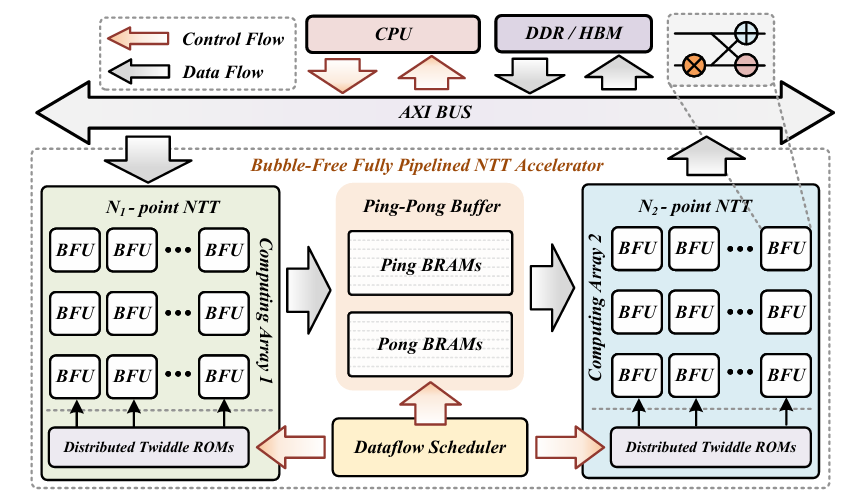
HyperNTT: An Ultra-High Throughput Number Theoretic Transform Accelerator for FHE (Accepted)
Yan Xu, Xiyan Dong, Jiarui Wang, Leyan Zhang, An Wang, Xinghua Wang, Liehuang Zhu, Jingqi Zhang
IEEE International Symposium on Circuits and Systems (ISCAS) 2026
An ultra-high throughput NTT accelerator for FHE with conflict-free dataflow and FPGA-optimized Montgomery reduction.
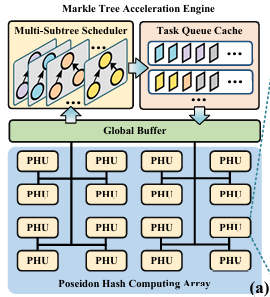
PhotoMT: Accelerating Zero-Knowledge Proofs with a Photonic-Electronic Merkle Tree Engine (Accepted)
Yan Xu, Mengquan Li, Shu Li, Zhaoyuan Zhang, Kenli Li
The 63nd ACM/IEEE Design Automation Conference (DAC) 2026
A photonic-electronic collaborative Merkle tree engine for ZKP acceleration, achieving up to 20.5× throughput improvement over ASIC designs.
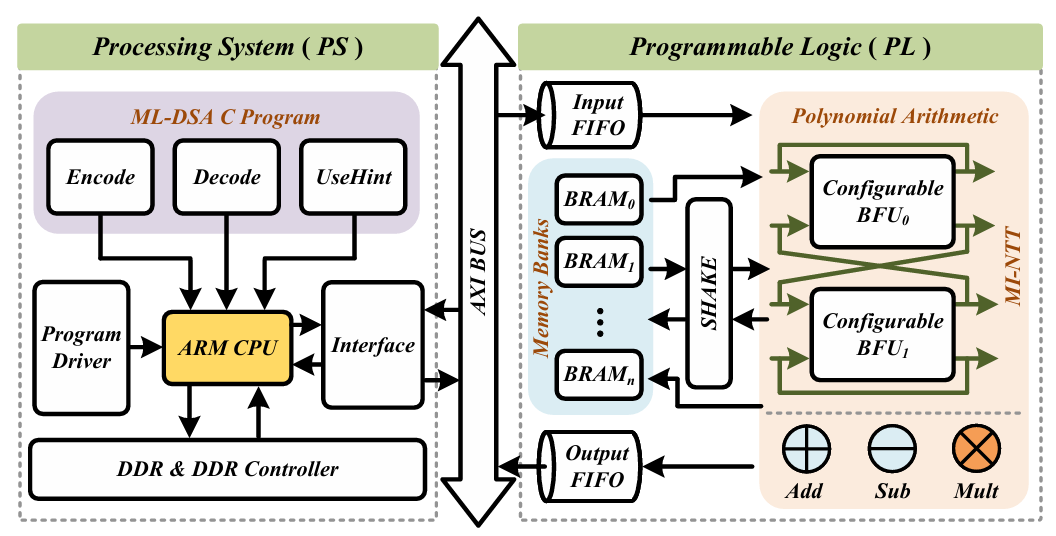
Safe-IoT: A Memory-Efficient HW/SW Co-Designed ML-DSA Accelerator for IoT Edge Devices (Accepted)
Yan Xu, Jingqi Zhang, Mengquan Li, Xinghua Wang, An Wang, Liehuang Zhu
The 63nd ACM/IEEE Design Automation Conference (DAC) 2026
A memory-efficient HW/SW co-designed ML-DSA accelerator for IoT edge devices, featuring MI-NTT and LUT-based modular multiplier.
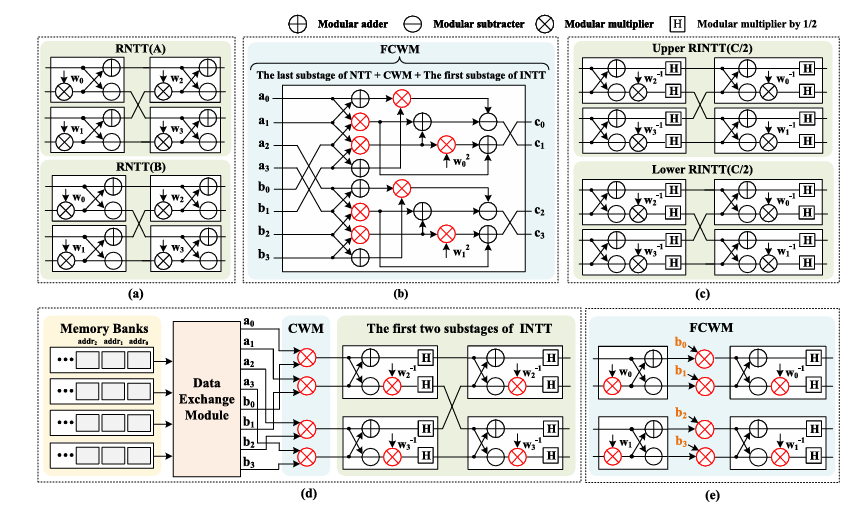
Meta: A Memory-Efficient Tri-Stage Polynomial Multiplication Accelerator Using 2D Coupled-BFUs
Yan Xu, Ling Din, Penggao He, Zhaolun Lu, Jiliang Zhang
IEEE Transactions on Circuits and Systems I: Regular Papers 2025
Built on FPGA, Meta provides specialized hardware acceleration for cryptographic operators, with optimized support for NIST-standardized post-quantum algorithms.
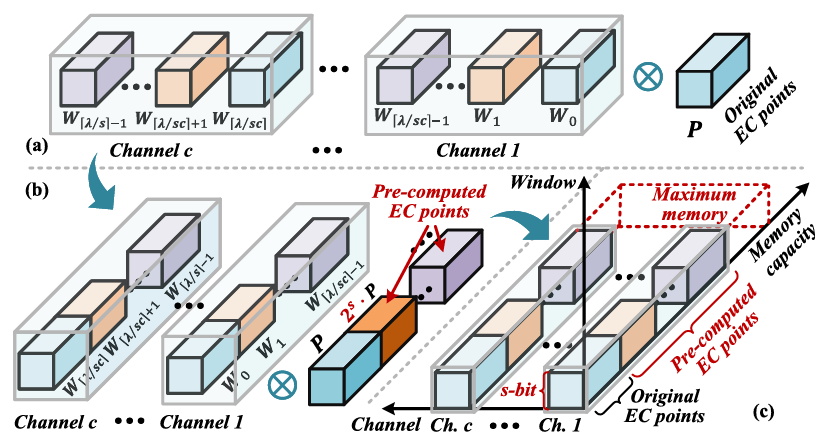
Fama: An FPGA-Oriented Multi-Scalar Multiplication Accelerator Optimized via Algorithm-Hardware Co-Design
Yan Xu, Jinqi Zhang, Xiyan Dong, An Wang, Xinghua Wang, Liehuang Zhu
IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems 2025
FAMA is an FPGA-oriented accelerator for Multi-Scalar Multiplication (MSM), a key bottleneck in zero-knowledge proofs, achieving over 184× speedup over CPUs and superior efficiency over other FPGA designs through algorithm-hardware co-design.
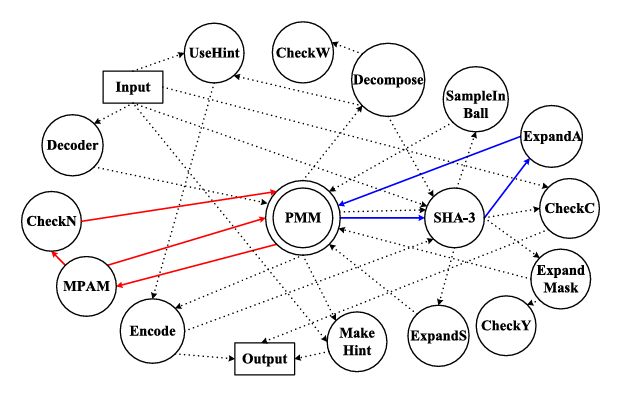
An Area-Efficient ML-DSA Accelerator With Interleaved and Dynamic Execution
Jinwei Pu, Yan Xu, Yuan Zhang, Jiliang Zhang
IEEE Transactions on Circuits and Systems I: Regular Papers 2025
An area-efficient ML-DSA accelerator leveraging interleaved and dynamic execution techniques, achieving significant improvements in area-time product over prior art.